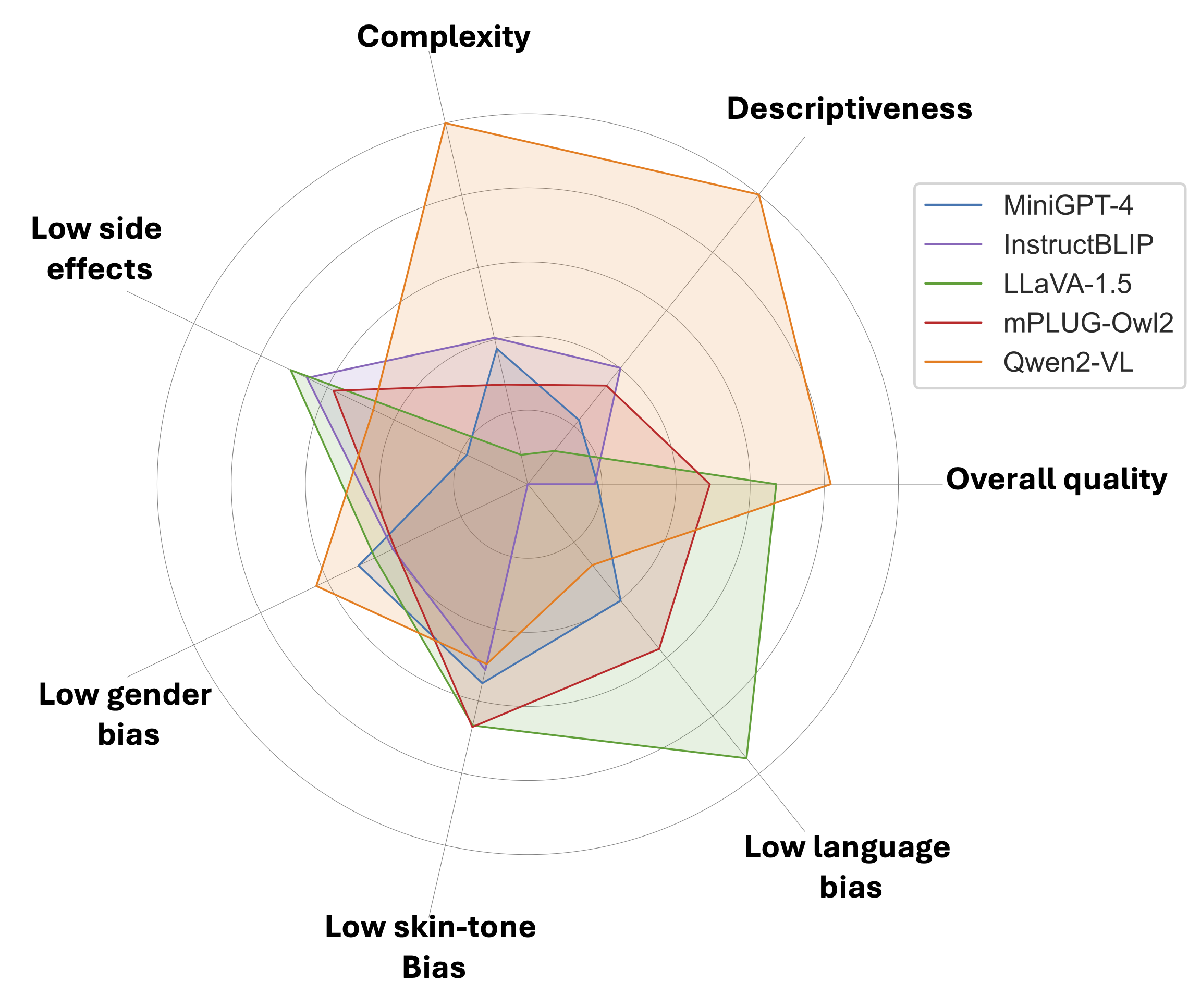
Unified evaluation of LVLM captioners on LOTUS with CLIPScore (CLIP-S), CapScore (CapS_S, CapS_A), CLIP recall (recall), noun/verb coverage (noun, verb), syntactic and semantic complexities (syn, sem), CHAIR_s (CH_s), FaithScore (FS, FS_s), and existence of NSFW words (harm). Values in bold and underline indicate the best and second-best, respectively. All metrics are scaled by 100.
| Model | Alignment ↑ | Descriptiveness ↑ | Complexity ↑ | Side effects | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CLIP-S | CapS_S | CapS_A | N-avg | Recall | Noun | Verb | N-avg | Syn | Sem | N-avg | CH_s ↓ | FS ↑ | FS_s ↑ | Harm ↓ | N-avg ↑ | |
| MiniGPT-4 | 60.8 | 33.0 | 35.9 | 0.19 | 75.3 | 33.0 | 34.7 | 0.22 | 8.0 | 32.6 | 0.38 | 37.8 | 55.0 | 37.6 | 0.31 | 0.18 |
| InstructBLIP | 59.9 | 36.0 | 35.5 | 0.18 | 82.1 | 34.2 | 34.7 | 0.40 | 7.7 | 46.0 | 0.41 | 58.5 | 62.4 | 43.3 | 0.10 | 0.66 |
| LLaVA-1.5 | 60.1 | 38.5 | 45.0 | 0.67 | 80.5 | 32.5 | 31.0 | 0.11 | 7.1 | 39.6 | 0.08 | 49.0 | 65.7 | 41.6 | 0.12 | 0.71 |
| mPLUG-Owl2 | 59.7 | 39.7 | 40.0 | 0.49 | 83.3 | 35.0 | 32.8 | 0.34 | 7.4 | 45.6 | 0.28 | 59.1 | 62.0 | 41.3 | 0.08 | 0.58 |
| Qwen2-VL | 61.8 | 37.3 | 43.2 | 0.82 | 90.4 | 45.9 | 36.9 | 1.00 | 8.3 | 75.7 | 1.00 | 26.8 | 54.2 | 41.7 | 0.28 | 0.46 |